深度学习的发展史 在今天直接主导了人工智能方向
2016.09.30 08:22 人工智能概念股

过去四年来许多领域的技术都取得了跨越性的发展。其中,最引人瞩目的是智能手机的语音识别功能比以往有了显著提升。当我们用声音命令手机给另一半打电话时,我们能够与他们取得联系,手机没有再将电话错拨给陌生人或已经不在一起的那个人。
实际上,我们现在越来越多地通过对话与计算机互动,无论是亚马逊的 Alexa、苹果的 Siri、微软的 Cortana,还是谷歌许多产品中的语音反馈功能。中国搜索巨头百度表示,使用语音界面的用户在过去 18 个月翻了三倍。
机器翻译和其他语言处理也有了长足的发展,谷歌、Facebook、微软和百度每个月都有新功能发布。谷歌翻译现在能提供 32 种语言对的语音翻译(输入是语音输出的也是语音),提供包括宿务语、伊博语、祖鲁语在内的共 103 种语言的文字翻译。谷歌邮箱应用有 3 种现成的自动回复。
接着要说的当时图像识别方面的进展。还是上面那 4 家公司,都有产品供你搜索或自动组织没有明确标签的照片。你可以要求系统显示所有带有狗的照片,或者有雪的,甚至抽象些比如含有拥抱场景的。这些公司都有研发中的产品,可以自动生成一句话那么长的图说。
深度学习推动计算产业逼近新的拐点
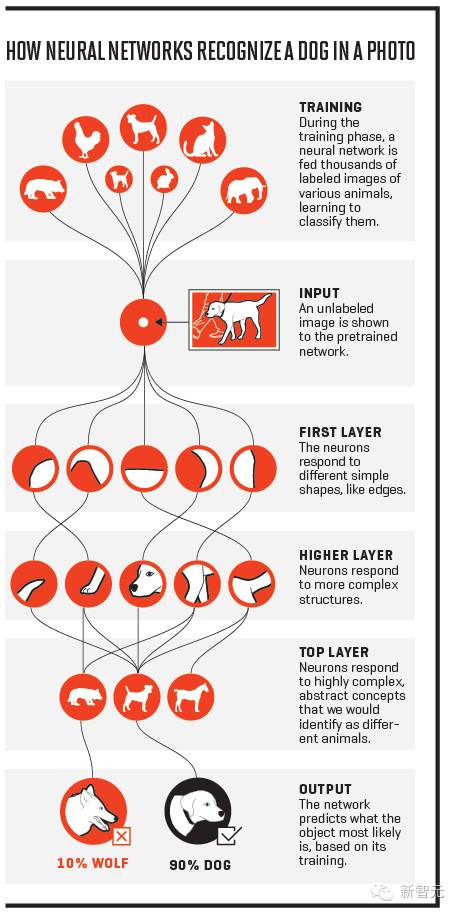
试想,要搜集含有狗的照片,应用程序必须识别出从吉娃娃到德国牧羊犬这么多种类的狗,还不能因为小狗上下颠倒或左边右边被雪被雾遮住了一块就被骗过。同时还要排除狼和猫。只靠像素。这究竟是怎么做到的?
图像识别技术的发展影响之深,已经远不止在你手机上很炫酷的社交应用。医疗初创公司声称,他们马上就能用计算机分辨 X 光片、MRI 和 CT 扫描图片,而且比放射学家读得更准更快,上至诊断预防癌症,下至加速发现治病救命的新药。更好的图像识别技术对于机器人、无人机以及自动驾驶汽车而言也是至关重要的。自动驾驶汽车在今年 6 月登上了本刊的封面报道。福特、特斯拉、Uber、百度和谷歌的母公司 Alphabet,都在公路上测试自动驾驶的原型样车。
但大多人没有意识到的是,所有这些突破实际上都是一样的。它们都受益于人工智能技术当中的深度学习,或者用大部分研究人员爱用的词形容——深度神经网络。
关于神经网络最不可思议的事情是,没有人曾经编程让计算机去执行这些任务。实际上,没有人能够做到这一点。程序员不再编程,而是提供给计算机一个学习算法,然后用海量的数据去训练它,这一过程会使计算机自己学会如何分辨需要分辨的物体、单词或句子。
一句话,这样的计算机可以自己教自己。用图像处理器巨头英伟达 CEO 黄仁勋的话说,“本质上说就是让软件写软件”。英伟达在大约 5 年前便看准深度学习,对这项技术做了大力投资。
神经网络也并非新兴技术。其概念可以回溯到上世纪 50 年代,而神经网络很多重要的算法突破都发生在 20 世纪 80 到 90 年代。让情况有所不同的是,如今的科学家终于将强大的计算力和海量的数据握在手中——从图像、视频、音频到文本,互联网上到处都是数据——而且人们发现,数据是让神经网络运行良好的关键。“这是深度学习的寒武纪大爆发,”投资公司 Andereesen Horowitz 的合伙人 Frank Chen 说。
这一剧变引发之下,AI 创业公司数量暴涨,根据调研公司 CB Insights,AI 投资额在过去一季度超过了 10 亿美元。2016 年第二季度有 121 轮融资,而 2011 年同期只发生了 21 笔。投资额从 2011 年第二季度到 2016 年第二季度超过 75 亿美元,其中有 60 多亿美元都是在 2014 年后产生的。(今年 9 月,5 家 AI 巨头——亚马逊、Facebook、谷歌、IBM 和微软——成立了一个非盈利组织,旨在促进公众理解 AI 技术并就伦理、操作规范展开调查。)
2012 年时,谷歌有两个深度学习项目。现在这个数字超过了 1000。根据一位谷歌发言人,现在谷歌所有主要产品分区中,从搜索、安卓、Gmail、翻译、地图、YouTube 到无人车,都有深度学习的影子。IBM 旗下的 Watson 赢得 Jeopardy 时虽用了人工智能,但没用到深度学习。但现如今,Watson CTO Rob High 表示,Watson 提供的 30 多种服务都因为深度学习而得到增强。
5 年前根本没有听说过深度学习的投资人,如今对于初创公司没有深度学习技术感到无比焦虑。“我们身处这样一个时代,”Chen 认为:“将来每个人都必须能够编写复杂的应用程序。”很快人们就会说,“你们自然语处理的版本在哪里?”“我该怎么跟你的 App 对话?因为我懒得打字。”
这些公司已经将深度学习整合进了每天的工作日程。微软研究院的 Peter Lee 说:“我们的销售团队使用神经网络与买房取得联系。”
硬件市场同样感受到了震动。摩尔定律带来芯片升级换代,更重要的是英伟达生产的图像处理器在进行深度学习计算时要比传统 CPU 快上 20 到 50 倍。过去的 8 月份,英伟达公布第 3 季度财报,数据中心这部分的销售额是去年同期的两倍多,达到了 1.15 亿美元。英伟达的 CTO 告诉投资人,大部分的增长来自深度学习。在 83 分钟的投资人会议里,深度学习被提到了 81 次。
芯片巨头英特尔当然没有什么都不做。在过去的两个月里,英特尔收购了 Nervana Systems(超过 4 亿美元)和 Movidius(金额未公开),两家针对深度学习做技术的公司。
至于谷歌,则在 5 月份公布它在过去一年多的时间里,偷偷使用自己的定制芯片 TPU 加速深度学习。
企业或许真的到了又一个转折点。百度首席科学家吴恩达说:“很多 S&P 500 CEO 都想着自己要是早些开始思考互联网战略就好了。再过 5 年,很多 S&P CEO 会想着自己要是早些思考 AI 战略就好了。”
在吴恩达看来,拥有深度学习的 AI 比互联网还强大。他说:“AI 是新的电力,就像 100 年前电力引发产业革命一样,AI 也会改变许许多多的行业。”
从感知机到 AlphaGo,你知道的和不知道的深度学习
你可以将深度学习看做一个子集里包含着一个子集。“人工智能”涵盖很广,传统的逻辑推理和符号系统也在其中,这门学科的目的是让计算机和机器人以一种至少表面看来很像思考的方式解决问题。其中,有一个叫做机器学习的领域,里面有很多重要的数学技巧,计算机可以以此优化性能。最后,在机器学习领域里,还有一个子领域叫深度学习。
百度的吴恩达说,你可以把深度学习看为“从 A 到 B 的映射”。“你可以输入一段音频然后输出录音,那就是语音识别。”吴恩达说,只要你有数据训练软件,可能性就是无限。“你可以输入电子邮件,输出可以是:这是不是垃圾邮件?”输入贷款申请,输出可以是顾客归还这笔款项的可能。输入一组用车的用户数据,输出就可以是接下来将汽车派往哪里。
从这个观点来说,深度学习将改变几乎整个产业。“既然计算机视觉真的起作用,会发生一些根本性的变革。”谷歌大脑计划的主管 Jeff Dean说,他又不安地变换了一下说法:“既然计算机已经睁开了它们的眼睛。”
这是否意味着现在该是要为“奇点”——超级智能机器开始不需人类参与地自行优化,引发超级可怕的结果的一个假定时刻——做好准备的时候?
还不是。神经网络在识别模式方面表现良好——有时甚至和人类一样好或超过人类。但它们没有理性。
深度学习历史关键点:1958年康奈尔心理学家罗森布拉特推出感知机,1969年明斯基出书质疑神经网络,1986年Hinton等人发明训练多重神经网络纠错的方法。

最初的革命火花开始于 2009 年。那年夏天微软的 Lee 邀请了神经网络先驱,多伦多大学的Geoffrey Hinton 来参观。钦佩于 Hinton 的研究,Lee 的团队用神经网络做了语言识别方面的实验。Lee说:“我们对结果非常震惊,我们得到了比原型高 30% 的准确率。”
2011 年,微软推出了应用深度学习技术的商用语言识别产品。谷歌在 2012 年 8 月跟着推出同类产品。
但真正的转折点出现在 2012 年 10 月。在意大利佛罗伦萨的一个工作室,斯坦福人工智能实验室的负责人,同时也是著名的年度 ImageNet 计算机视觉大赛创始人李飞飞,公布 Hinton的 两个学生做了一个识别物体软件,准确率是当时最好的同类产品的两倍。“这个成果非常惊人,”Hinton 说:“它说服了曾经的许多怀疑论者。”(在去年的大赛中,新的深度学习产品已经超越了人类的表现。)

深度学习历史关键点:1989年LeCun用卷积神经网络识别手写体,1991年递归神经网络发明,1987年IBM深蓝战胜卡斯帕罗夫。
图像识别方面的成就像一把发令枪,启动了一场人才争夺赛。Google 得到了 Hinton 和他那两位赢了大赛的学生,Facebook 和法国深度学习天才 Yann LeCun 签约,LeCun 曾在 20 世纪 80 年代和 90 年代开创了深度学习算法并赢得 ImageNet 大赛。百度则得到了斯坦福 AI 实验室的前负责人吴恩达,他曾在 2010 年帮助推出并领带专注深度学习的谷歌大脑项目。
人才争夺热潮自此愈演愈烈。今天,微软的Lee说,“这个领域的人才战相当血腥,一流的人才就像NFL足球运动员。”
今年 68 岁的 Geoffrey Hinton 第一次听说神经网络是在1972年,当时他正在爱丁堡大学开始写自己的硕士毕业论文,主题是人工智能。由于本科期间在剑桥大学主修实验心理学,Hinton对神经网络充满热情,神经网络由软件构建,从人类大脑中神经元网络的运作方式获得启发。当时,神经网络并不受欢迎。“每一个人都认为他们疯了”,他说。但是Hinton选择迎难而上。

深度学习历史关键点:2007年李飞飞创立ImageNet;2011年微软将神经网络引入语音识别;同样2011年IBM Watson赢得Jeopardy冠军。
神经网络为计算机的学习提供了一种孩子式的学习方式,从经验,而不是从人类的编程设定中进行学习。“当时,大多数的AI 都是从逻辑推理中获得启发”,他回忆说,“但是逻辑推理是人类在人类长大的时候才具备的能力,2-3岁的孩子并不会做逻辑推理。所以,我认为,对于智能来说,神经网络是比逻辑好得多的范式”。(逻辑从某种程度来说,是Hinton 家族的传家宝。他的家族中诞生了多位杰出的科学家,他是19世纪著名数学家George Boole的玄孙,Boolean 搜索、逻辑和线性代数都是以这位数学家的名字命名的)。
20世纪50年代至60年代,神经网络在计算机科学家中变得流行起来。1958年,Cornell 研究中心的心理学家 Frank Rosenblatt在一个海军支持的项目中,开发了一个神经网络原型,当时他称为感知机(Perceptron)。模型使用的是一个穿孔卡片计算机,占满了整个房间。在经过50次尝试之后,计算机学会了分辨左边标记几号和右边标记记号的图片。针对这一事件,《纽约时报》的报道文章写到,“今天,(美国)海军发布了一个电子计算机原型,被认为可以行走、说话、看、写、自我重生,并具有自我存在的意识”。
感知机的软件只有一层类似神经元的节点,后被证明是有局限的。但是,研究者相信,随着神经网络层数变多,或者变深,它可以做的事情会更多。
Hinton 解释了这一创意的基本原理。假设一个神经网络在理解一批照片,其中一些照片上有鸟。“所以,输入层会进来像素,进而,整个单元的第一层会探测到边缘。暗的一边,亮的在另一边”。下一层的神经元,通过分析第一层得到的数据,将学会探测“比如边角之类的,两条边组成一个角”,他说。这些神经元中,有一个可能会对鸟的轮廓构成的角产生强烈的反应。
下一层,可能会发现更多复杂的配置,比如,一个圆圈中排列的许多个角”,这一层中的神经元可能会对鸟的头部作出反应。在一个更深的层,一个神经元可能会探测到头部圆圈中反复出现的嘴部轮廓。“这构成了一个很好的线索,可以判断出这可能是鸟的头部”,Hinton说。每一个更深层次的神经元都会对更加复杂和抽象的概念作出反应,直至最后有一层对我们概念中的“鸟”作出匹配反应。

深度学习历史关键点:2012年谷歌大脑识别猫脸(6月),8月谷歌将神经网络引入语音识别,10月Hinton的学生在ImageNet竞赛夺冠,成绩大幅提升;2013年5月谷歌用神经网络改善照片搜索功能。
但是,要进行学习,一个深度神经网络需要做的不仅仅是在各层神经网络中传递信息。它还需要一个方法来验证是否获得了争取的结果,如果没有,就把信息反馈回浅层的神经网络,调整活动,改进结果。这才是学习发生的地方。
20世纪80年代早期,Hinton在这一难题上持续钻研。法国的一位研究者Yann LeCun 也在默默耕耘,当时他刚在巴黎开始自己的研究生生涯。LeCun被Hinton发表于1983年的一篇论文震惊到了,这是一篇谈多层神经网络的文章。这些术语在当时都不是正规的,LeCun回忆说,在当时要发表一篇提及“神经元”或者“神经网络”的论文,简直比登天还难。所以,他以一种隐晦 方法写成了这篇论文,以通过同行评议。但是我认为这篇论文是超级有趣的。
两位学者两年之后见面,一拍即合。
1986年,Hinton和两位同事写了一篇非常有影响力的论文,为error-correction难题提供了一个算法解决方案。LeCun说:“他的这篇论文奠定了第二波神经网络发展的基础”。重新点燃了研究领域的兴趣。
在 Hinton 那读完博士后后,LeCun 在1988年进入AT&T 贝尔实验室,在接下来的10年中,他做了很多基础性的工作,有一些在今天大部分的图像识别任务中都还在使用。1990年,贝尔实验室资助的NCR项目把一个神经网络驱动的设备进行商业化,后被银行广泛采用,可以读取支票上的手写字迹。LeCun说。同时,两位德国研究者 Sepp Hochreiter 和Jürgen Schmidhuber独立地开发了一种算法,奠定了今天自然语言处理应用的基础。虽然有这些进步,但是到20世纪90年代中期,神经网络再次陷入低潮。主要原因是受到当时计算能力的限制。这一情形持续了差不多10年,直到研究者发现GPU的加速后,才再次崛起,此时的计算能力已经提高了3到4个维度。

深度学习历史关键点:2014年谷歌收购DeepMind;2015年12月微软ResNet图像识别准确率超越人类;2016年3月AlphaGo战胜李世石。
但是,还有一个大学依然缺乏:数据。虽然互联网带来了大量数据,但是,绝大部分数据,尤其是图像数据,依然是没有标签的,但这又是训练神经网络不可或缺的。这时候,斯坦福的教授李飞飞进入了这一领域。“我们的预期是,大数据会改变机器学习的运作方式”,她在接受采访时谈到,“数据驱动的学习”。
2007年,她发布了ImageNet,打算组建一个免费数据库,包含了超过1400万标签图像。2009年,这一数据库公开,下一年,她组织了一个年度的竞赛,来激励并发表计算机视觉上的重要突破。
2012年10月,Hinton 的两个学生拿下 ImageNet冠军,深度学习的到来变得明晰了。
但是,当时大众已经听说了深度学习,虽然是通过其他的事件。2012年6月,谷歌大脑团队发布了“猫试验”项目,在社交网络上获得广泛传播。这一项目实际上探索的是一个深度学习中一个还未解决但非常重要的领域——无监督学习。当下,几乎所有的商业深度学习产品使用的都是“监督学习”,也就是说,神经网络要经过标签数据的训练、在“无监督学习”的条件下,神经网络获得的是无标签数据,只能简单地参考递归模型。研究者会很喜欢看到有一天能掌握无监督学习,让机器能自我学习,就像婴儿一般。
深度学习四巨头:产品、人才和战绩
谷歌在 2011年推出专注深度学习的谷歌大脑计划(Google Brain Project),在2012年中期发布基于神经网络的声音识别产品,2013年3月得到了神经网络先驱Geoffrey Hinton的加入。谷歌现在有超过1000个深度学习项目,研究的领域相当宽泛,包括Android,Gmail,照片、地图、翻译、YouTube和无人车。2014年谷歌收购DeepMind,今年3月DeepMind的加强深度学习项目AlphaGo打败了世界围棋冠军李世石,这对人工智能来说是标志性的事件。
微软在 2011年推出商业化的语音识别产品,包括Bing语音搜索和X-Box语音处理。微软现在在搜索排序、照片搜索、翻译系统等方面广泛利用神经网络。“如何转化这些渗透性的影响非常不易。”Lee说。微软去年赢得了图像识别大赛,九月它在语言识别的错误率上取得了突破性的进展:错误率降到6.3%。
Facebook在2013年12月聘请了法国神经网络创新者Yann LeCun作为它的新AI实验室的带头人。Facebook平均每天使用神经网络翻译来自超过40种语言国家的20亿用户的帖子,这些翻译的内容每天被8000万用户阅读。(Facebook的用户中有近一半不是英语用户。)Facebook也在照片搜索和照片排列中使用神经网络,而且它正在开发一个功能,能对无标签的照片生成语音标签以帮助视障人士。
百度在2014年4月聘请了谷歌脑计划的前负责人吴恩达作为它的AI实验室的领头人。百度作为中国领先的搜索和网络服务企业,把神经网络应用于语音识别、翻译、图片搜索以及无人驾驶等项目中。对中国来说,语音识别是非常关键的领域,因为手机输入中文相当困难。百度说,过去18个月里使用语音接口的用户数量增长了三倍。
深度学习和蓬勃发展的医疗领域
并不让人意外,大部分深度学习应用的商业部署都出自谷歌、微软、Facebook、百度、亚马逊等公司——他们拥有深度学习计算所需要的大数据。很多企业都在开发更加实用、更多功能的“聊天机器人”,作为自动客户服务代表。
IBM 和微软这样的公司也在帮助商业客户采纳深度学习驱动的应用,比如语音识别交互和翻译服务。同时,像亚马逊的云服务提供了便宜的 GPU 驱动深度学习计算服务,让其他公司开发自己的深度学习软件成为可能。大量的开源软件,比如 Caffe、谷歌的 TensorFlow 和亚马逊的 DSSTNE,共同促进了创新的进程,同时也创造了一种开源共享的文化,进而有许多研究者在一个数据集上获得成果以后会立刻发布出来,不需要再等待漫长的同行评议。
对深度学习的应用,许多最令人兴奋的尝试发生在医疗领域。我们已经知道神经网络在图像识别上可以做得很好。领导 Andreessen Horowitz 生物投资部门的观察者、斯坦福教授Vijay Pande 说,“医生的工作中,有很大一部分就是图像识别,不管我们说的是放射科、皮肤科、眼科或者别的什么科”。
初创公司 Enlitic 使用深度学习来分享 CT 和 MRI 扫描结果。公司 CEO Igor Barani 此前曾是加利福尼亚大学的放射肿瘤学的教授,他说,Enlitics 的算法在探测和分类肺部肿瘤的恶化上超过了 四位肿瘤学专家。(该研究还没有通过同行评议,也没有获得美国食品药品管理局(FDA)的认可。
默克公司(Merck)正在尝试使用深度学习来加速药品的发现,在旧金山的一家初创企业 Atomwise 也在做同样的事。神经网络通过观看3D图像(图像中上万个分子可能会被用作药材),预测这些分子在抵抗病原体上的适用性。这些公司正在使用神经网络,尝试提高人类已经在做的事情。但是,也有一起公司在尝试做一些人类无法完成的是,27 岁的计算机生物学博士 Gabriel Otte 创办了 Freenome,其目标是从样本血中诊断癌症。使用深度学习,他让计算机找到脱细胞DNA和一些癌症的关联性。“我们发现了一些新颖的特征,这是还没被癌症生物学家发现的。”
Andreessen Horowitz 在考虑对 Freenome 进行投资时,Pande 给OTTE 设置了5个盲样,其有两个是正常的,另外三个是患癌的。Otte 五个检测全正确了,然后获得了投资。
一个放射科医生一生可能会看上万张扫描图像,但是,一台计算机可能会看上千万张。“让计算机来解决图像的问题,这听起来并不疯狂”,Pande说,“因为他们能处理的数据远比人类多得多”。
计算机的潜力不仅在于更准确、更快的分析,而是能带来服务的民主化。随着技术标准化,最终每一位患者都能受益。也许在以一种人们还没有想到的方式,与其他的人工智能技术进行融合,形成一个完整的工具箱,人们才会感受到深度学习最大的影响力才。例如,谷歌的 DeepMind 通过把深度学习与相关的技术——增强学习相结合,已经取得了一些震撼的成功。结合这两种技术,他们创造了AlphaGo,让这一程序在今年3月份击败了围棋世界冠军,这被认为是 AI 领域具有里程碑意义的事件。与 1997 年击败国际象棋冠军的 IBM 深蓝不一样,AlphaGo 没用使用决策树进行编程,也没有使用如何评估棋盘位置的等式,没有使用 if-then 规则。“AlphaGo 学习下围棋主要是从自我对弈和观察其他专业棋手的对弈中进行”,DeepMind 的 CEO Demis Hassabis 说。
一个游戏可能看起来像是人工设置的环境。但是 Hassabis认为,游戏的技术可以被用到现实世界的难题中。事实上,8月份的时候,谷歌报告说,通过使用与 AlphaGo 类似的方法,DeepMind 能够将谷歌数据中心的能源效率提升 15%。在数据中心,可能有 120 种变量在影响电力消耗,Hassabis 说,“你可以换风扇、开窗户、调整计算机系统等等,这些都是电力消耗的地方。从传感器、温度计之类的地方,你可以获取数据。这和围棋棋盘类似。通过试错,你可以知道正确的方向是哪里”。
“这很好,”他继续说,“每年,你可以省下上千万美金,并且对环保来说也是好事。世界上的数据中心消耗了大量的能源。我们非常希望能大量地减少这些消耗,甚至是在国家电网的层面”。
聊天机器人是挺好。但这个,才是真正厉害的应用。
人工智能概念股:埃斯顿、科大智能、汉王科技、江南化工、华东数控、和而泰、中科曙光、永创智能、北京君正、通富微电、永创智能、劲拓股份。
人工智能概念股
那么问题来了:最值得配置的人工智能概念股是哪只?即刻申请进入国内首个免费的非公开主题投资交流社区概念股论坛参与讨论!

申明:本文为作者投稿或转载,在概念股网 http://www.gainiangu.com/ 上发表,为其独立观点。不代表本网立场,不代表本网赞同其观点,亦不对其真实性负责,投资决策请建立在独立思考之上。





